This article explains the Space-Based architecture style, detailing its use of data and processing grids to achieve high scalability and elasticity. Learn about its benefits, such as in-memory state management and low latency, as well as its trade-offs and operational considerations for high-scale systems.
Definition
Space-based architecture removes the single-database bottleneck by pushing hot state and work into a cluster that holds data in memory and executes logic where that data lives. It’s built for bursty or sustained high load—think flash sales, feeds, or real-time analytics—while accepting eventual consistency for the system of record.
Space-based systems distribute both data and processing across many identical nodes. A shared space (an in-memory data grid) shards and replicates hot data; processing units run application logic against that grid; persistence to a database is handled off the hot path, typically via asynchronous write-behind. The result is horizontal scale, low-latency access, and graceful handling of traffic spikes.
Intent & Forces
The intent is to achieve extreme throughput and elasticity under variable loads, without a single choke point. Typical forces include unpredictable traffic, large numbers of concurrent sessions, and the need to co-locate compute with data. The style favors in-memory partitioning, replication, and parallelism over global transactions, cross-partition joins, and strict immediate consistency.
Structure
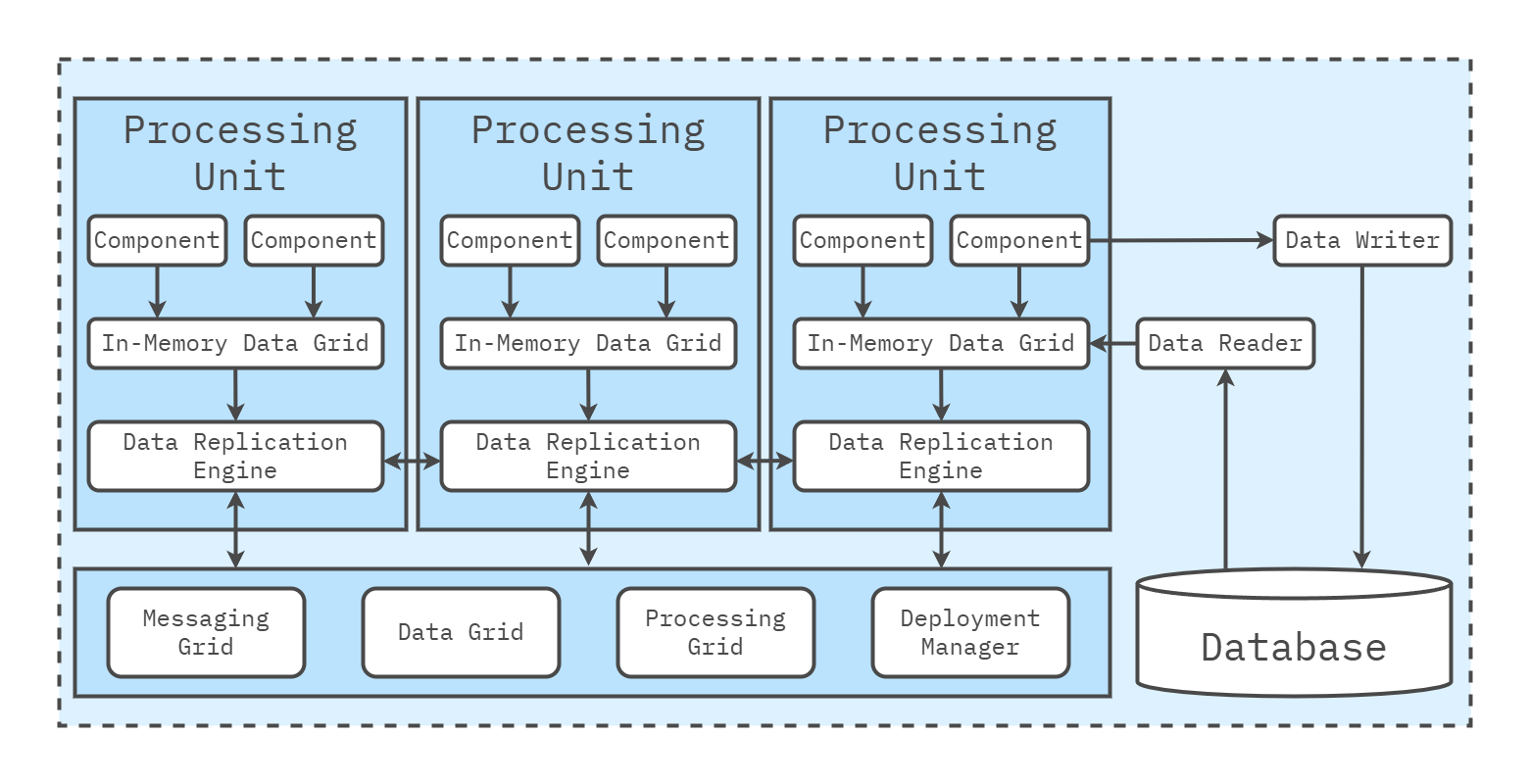
Space-based systems are built from a small set of moving parts that reflect “compute-near-data”:
- Processing units run application logic and are designed to be stateless with respect to local memory, relying on the grid for state and session data.
- Data grid shards (partitions) and replicates hot data across nodes; it is the primary read/write path for requests.
- Messaging grid moves events/commands between units and nodes; it also coordinates rebalancing.
- Persistence agents stream changes from the grid to cold storage (database) asynchronously for recovery and reporting.
- Deployment manager adds/removes nodes and rebalances partitions to absorb spikes.
Dependency Rules
Processing units depend on grid contracts, not on each other’s internals. Cross-partition access happens through the grid’s APIs and routing, not ad-hoc calls. Avoid hidden shared state outside the grid; keep utilities domain-agnostic. When units must collaborate, they should communicate via the messaging grid or events rather than using direct in-process backdoors.
Data & Transactions
Treat the in-memory grid as the authoritative source for hot-path reads and writes; treat the database as a system of record and recovery. Partition data with clear ownership (one writer per shard). Favor local, short-lived transactions scoped to a partition; handle cross-partition work with saga-like compensations or asynchronous coordination. Accept eventual consistency between grid and cold store; design reconciliation and replay for recovery.
Example
During a flash sale, requests are routed to any node. The node’s processing unit validates the cart and reserves inventory in the grid partition that owns those SKUs. The reservation is replicated to a backup partition; the user session also lives in the grid. A persistence agent later writes the confirmed order to the database. If a node fails, partitions fail over to replicas and requests are re-routed—no central database round-trips on the critical path.
Design Considerations
Where It Fits / Where It Struggles
Space-based systems excel in extreme or spiky traffic, session-heavy portals, stream/analytics preparation, trading/tick processing, and other domains where latency and throughput dominate, and eventual consistency is acceptable. It struggles where strict ACID across sources, global transactions, or heavy cross-shard queries are non-negotiable, and where teams cannot absorb the operational complexity of clustering, rebalancing, and high-load testing.
Trade-offs
- Optimizes: throughput and low latency; elastic scale by adding nodes; fault isolation via partition replication.
- Sacrifices: immediate global consistency; simple cross-aggregate queries; operational simplicity.
- Requires: effective partitioning, replication, and rebalancing; disciplined use of asynchronous persistence; robust observability.
Misconceptions & Anti-Patterns
- Keeping the central DB in the hot path. The grid exists to avoid database bottlenecks—persist changes off the hot path.
- Uneven partitions and overloaded nodes. Poor keys create hotspots; monitor and rebalance.
- Tight coupling between processing units. Cross-calls undermine scale; communicate via the grid or events.
- Ignoring network costs. Replication and messaging add latency; size partitions and replicas accordingly.
- Assuming strong consistency. Plan for drift and reconciliation between the grid and the cold store.
Key Mechanics Done Well
- Stateless units with grid-backed state. Keep business state in the grid so units can scale/relocate freely.
- Partition keys that follow access patterns. Choose keys that maximize locality and minimize cross-shard hops.
- Replica strategy per partition. Balance RPO/RTO with cost; test failover and rebalance regularly.
- Back-pressure and admission control. Use bounded queues and rate limits to prevent meltdowns during spikes.
- Asynchronous write-behind with audit trails. Persist events/changes reliably; rehearse recovery from cold store.
Combining Styles
SBA often wraps event-driven ingestion and change propagation at the edges, uses layered slices for admin/API surfaces, and applies modular-monolith boundaries to group related partitions and logic. Treat the grid as the backbone for hot paths and let slower, report-heavy needs flow through cold storage or read models fed from the grid.
Evolution Path
Start by moving the hottest aggregates and sessions into a small grid and co-locating logic as processing units. Add partitions and replicas as evidence accumulates. If a subset of functionality requires isolation or different scaling, extract that slice as a separate cluster or service with its own grid, maintaining stable contracts. Always size partitions for future growth and design rebalancing as a routine operation.
Operational Considerations
Operate the cluster like a living system: track partition distribution, replica health, rebalancing time, tail latencies, and grid hit ratios. Alert on skew, backlog, and failover events. Run chaos drills for node loss and network partitions. Capacity plans must account for working-set memory, replication overhead, and network bandwidth. Load tests should mimic burst patterns, not just steady-state.
Decision Signals to Revisit the Style
Re-evaluate when cross-partition joins dominate hot paths, when reconciliation drift creates user-visible errors, when rebalancing time violates SLOs, or when the cost/complexity of realistic performance testing exceeds the benefit over simpler styles. If strict ACID becomes mandatory end-to-end, consider consolidating hotspots or moving those workflows to a different space.
Recommended Reading
Web Resources
- Developer To Architect, Lesson 166 - Space-Based Architecture
Books
- Richards, M., & Ford, N. (2020). Fundamentals of Software Architecture: An Engineering Approach . O’Reilly Media.
- Chapter 15: Space-Based Architecture Style
Introduces processing and data grids, partitioning/replication, and asynchronous persistence, with guidance on when the style fits and when it does not.
- Chapter 15: Space-Based Architecture Style
- Richards, M. (2024). Software Architecture Patterns (2nd ed.). O’Reilly Media.
- Chapter 7: Space-Based Architecture
Explains how to remove the central DB from the hot path, co-locate logic with in-memory partitions, and stream changes to cold storage for recovery and reporting.
- Chapter 7: Space-Based Architecture