This article explains the Orchestration-Driven architecture style, detailing its use of central orchestrators and workflow contracts to manage complex business processes. Learn about its benefits, such as visibility and control, as well as its trade-offs and practical implementation strategies to effectively design and maintain an orchestrated system.
Definition
Orchestration-driven architecture coordinates work through a central orchestrator that calls services in a defined sequence. It provides visibility, control, and explicit error handling for complex business processes—at the cost of creating a new operational hotspot that must be scaled and governed carefully.
In the orchestration-driven style, a dedicated component (the orchestrator) owns the workflow: it invokes services, handles branching and retries, aggregates results, and records progress. Services remain modular and reusable, but their collaboration happens through the orchestrator’s contracts rather than ad-hoc calls between peers. This contrasts with choreography, where services react to events without a central conductor.
Intent & Forces
The style exists to make multi-step business processes explicit, observable, and governable. It is favored when the sequence really matters, when auditing is mandatory, and when you need one place to implement compensation, timeouts, and retries. The counterforces are the scalability of the orchestrator, the risk of over-coupling workflows to a single component, and the extra care required to keep services independent of workflow specifics.
Structure
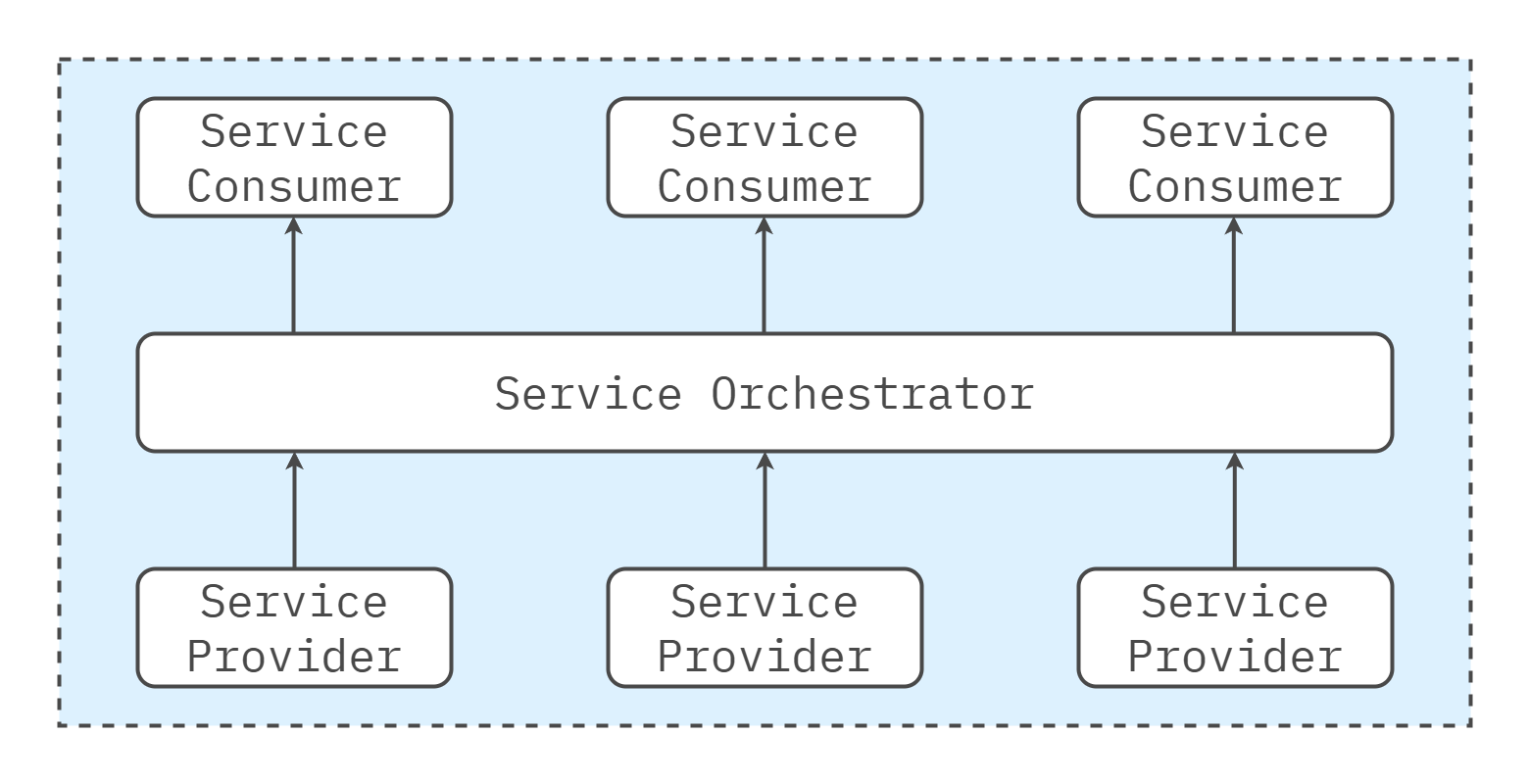
A typical solution has three parts: the orchestrator, the services, and the workflow definitions that bind them.
- Orchestrator executes workflows, evaluates conditions, manages timeouts/retries/compensations, and tracks state.
- Services encapsulate business capabilities and expose stable contracts (sync or async) that the orchestrator can call.
- Workflow definitions capture sequence, branching, joins, and data mapping—often modeled in BPMN or a similar DSL.
The communication mix is pragmatic: synchronous calls are used for short, user-facing steps, while asynchronous messaging is employed for long-running steps, integration, and resilience under load.
Dependency Rules
Keep workflow logic in the orchestrator and business rules inside services. Services should not depend on the orchestrator’s internals or on each other’s private state; all collaboration runs through published contracts or messages. If a service requires data owned by another, access it through that service’s API or its events—never its tables. These rules reduce tight coupling and preserve service reusability across different workflows.
Data & Transactions
Each service commits its own changes locally. The orchestrator coordinates the bigger picture with compensating actions rather than global transactions. Prefer idempotent service operations so that retries are safe, and include correlation IDs in calls and messages to enable end-to-end workflow tracing. Long-running steps should surface timeouts and cancellation cleanly; the orchestrator records progress and applies compensations if a branch fails.
Example
Consider order fulfillment. The orchestrator validates the order, then calls Inventory to reserve stock, Billing to authorize payment, and Shipping to schedule delivery. If Billing declines, the orchestrator triggers a compensation in Inventory to release the reservation and marks the workflow as failed with a reason code. All steps are visible in the workflow state; retries and backoff are policy, not ad-hoc code in each service.
Design Considerations
Where It Fits / Where It Struggles
It fits regulated or audit-heavy domains, multi-party integrations, and processes with clear ordering and compensations: e-commerce fulfillment, loan underwriting, patient intake, and claims processing. It struggles when services must evolve independently without central coordination, when hot paths demand ultra-low latency, or when workflows devolve into chatty, fine-grained RPC that the orchestrator cannot scale economically.
Trade-offs
- Optimizes: workflow visibility and control, centralized error handling, business alignment, reuse of services across flows
- Sacrifices: pure decentralization, some autonomy, and peak scalability if the orchestrator becomes a hotspot
- Requires: stable contracts, idempotent operations, compensation design, and strong observability on workflow state
Misconceptions & Anti-Patterns
- Monolithic orchestrator. Overloading the orchestrator with business logic or heavy computation makes it a bottleneck; keep it focused on coordination.
- Hard-coded flows. Baking sequences deep in code slows change; use declarative workflow definitions and version them.
- Synchronous everything. Long chains of blocking calls increase latency and fragility, introducing queues where steps can be executed asynchronously.
- Workflow logic inside services. Services should remain reusable; let the orchestrator own the process.
Key Mechanics Done Well
- Contract-first services with clear inputs/outputs and error semantics; publish SLAs so the orchestrator can set timeouts and retries intelligently.
- Compensation patterns defined alongside the happy path; test them with chaos drills.
- Observability by design: workflow IDs, step status, and correlation across calls/messages; dashboards for “in-flight,” “stalled,” and “failed with reason.”
- Scalable orchestrator topology: partition workflows by key, shard work across instances, and externalize state if needed to remove single-node limits.
Combining Styles
Orchestration and choreography are complements, not rivals. Use orchestration for the critical span that requires ordering, auditing, and compensation; let the rest of the ecosystem respond through events. Within each service, maintain a simple, layered slice; across services, prefer coarse-grained calls and asynchronous handoffs to avoid the “distributed monolith.”
Evolution Path
Start with a small number of high-value workflows. As evidence accumulates, splitting orchestration domains (e.g., by product line or region) promotes durable state stores if in-memory state becomes a limitation, and moves long-running or compute-intensive steps to asynchronous tasks. If a set of steps stabilizes and no longer needs central control, convert that span to choreography and keep the orchestrator focused on the truly critical parts.
Operational Considerations
Run the orchestrator like a product. Measure workflow completion time, step success rate, retry volume, and compensation frequency. Alert on stuck or aging workflows. Provide a console where operators can pause, resume, or abandon instances with audit trails. For reliability, design active-active orchestrator instances with idempotent step invocation and exactly-once effects via idempotency keys—not exactly-once delivery guarantees.
Decision Signals to Revisit the Style
Re-evaluate when the orchestrator CPU and queue depth dominate latency, when most steps have become independent and event-driven, when compensation logic overwhelms the happy path, or when workflow definitions change more frequently than you can safely roll them out. In these cases, narrow the orchestrated span, split orchestration domains, or switch parts of the flow to choreography.
Recommended Reading
Web Resources
- Developer To Architect, Lesson 43 - Microservices Orchestration Pattern
- Developer To Architect, Lesson 23 - Orchestration vs. Choreography
Books
- Richards, M., & Ford, N. (2020). Fundamentals of Software Architecture: An Engineering Approach . O’Reilly Media.
- Chapter 16: Orchestration-Driven Service-Oriented Architecture
Defines orchestrators, workflow definitions, synchronous and asynchronous communication, benefits and challenges, and contrasts orchestration with choreography.
- Chapter 16: Orchestration-Driven Service-Oriented Architecture